This blog post covers the work done in the last two weeks of the second phase of coding. I have updated the checklist of the deliverable for the second phase at https://saurabhshri.github.io/gsoc/ .
If you are wondering about the delay - I am not being lazy, blogging is one of the things I love the most. I am just a little busier than ever. 🙂
In the last blog post I mentioned that one of the tasks of this period would be to figuring out a proper way of handling FSGs so that they consider the garbage loop as well. So, after a lot of experimenting with different scenarios and different weights, I finally figured out a good enough approach with a consistent efficiency irrespective of the audio. Creating FSGs dynamically should not be considered as the most accurate approach as devising them manually based on audio could substantially increase the accuracy.
Here’s an example of one such FSG :
FSG_BEGIN CUSTOM_FSG
NUM_STATES 20
START_STATE 0
FINAL_STATE 19
# Transitions
TRANSITION 0 1 0.0909
TRANSITION 0 2 0.0909
TRANSITION 0 3 0.0909
TRANSITION 0 4 0.0909
TRANSITION 0 5 0.0909
TRANSITION 0 6 0.0909
TRANSITION 0 7 0.0909
TRANSITION 0 8 0.0909
TRANSITION 0 9 0.0909
TRANSITION 1 10 1.0 i
TRANSITION 2 11 1.0 was
TRANSITION 3 12 1.0 offered
TRANSITION 4 13 1.0 a
TRANSITION 5 14 1.0 summer
TRANSITION 6 15 1.0 research
TRANSITION 7 16 1.0 fellowship
TRANSITION 8 17 1.0 at
TRANSITION 9 18 1.0 princeton
TRANSITION 10 19 0.0909
TRANSITION 11 19 0.0909
TRANSITION 12 19 0.0909
TRANSITION 13 19 0.0909
TRANSITION 14 19 0.0909
TRANSITION 15 19 0.0909
TRANSITION 16 19 0.0909
TRANSITION 17 19 0.0909
TRANSITION 18 19 0.0909
TRANSITION 19 0 0.0909
FSG_END
This makes the grammar flexible and makes a room for allowing the cases where recognition doesn’t match the expected output!
The next part was to actually align the recognised words with the audio. Prior to this, the recognition and time detection based on frames was working. The very first step in this was to reset the time stream, so that the frame count can be with respect to zero. This eliminated the chances of error as we are not processing all samples, but only those samples which have utterances.
For each word, I found out the exact timing by dividing the frame count with the frame rate and converting it into milliseconds. This value was then added to the beginning timestamp of the samples for which they were recognised.
//the time when utterance was marked, the times are w.r.t. to this
long int startTime = sub->getStartTime();
long int endTime = startTime;
/*
* Finding start time and end time of each word.
*
* 1 sec = 1000 ms, thus time in second = 1000 / frame rate.
*
*/
startTime += sf * 1000 / frame_rate;
endTime += ef * 1000 / frame_rate;
They are also stored in an object of class recognisedBlock for later uses.
For the alignment with subtitle, the recognised words needed to be matched with subtitle text. A simple linear search would not be a preferred choice in this case, as it will provide erroneous results. For example, consider the case :
Actual : [Why] would you use tomato just why
Recognised : would you use tomato just [why]
So, if we search whole recognised sentence for actual words one by one, then Why[1] of Actual will get associated with with why[7] of recognised. This will not only result in incorrect tagging of word, but also the words in square bracket matches, sets the lastWordFoundAtIndex at 6, and the search stops.
To prevent this I am using a window based search approach where a word is searched only in the defined window thus, limiting the number of words it can look ahead, in order to prevent error of mismatching. This also enables user to define a window to look into.
searchWindowSize = 3;
Recognised : so have you can you've brought seven
|
---------------
| |
Actual : I think you've brought with you
Recognised : so have you can you've brought seven
|
-------------------
| |
Actual : I think you've brought with you
But since the recognition is not perfect, I perform a fuzzy search to find the match instead of directly comparing the words. The fuzzy search is performed by calculating the Levenshtein distance between the words. I then use this distance to find out how much are the words similar. If the words have similarity of 75% or above, I consider them a match! This percentage of course is user configurable.
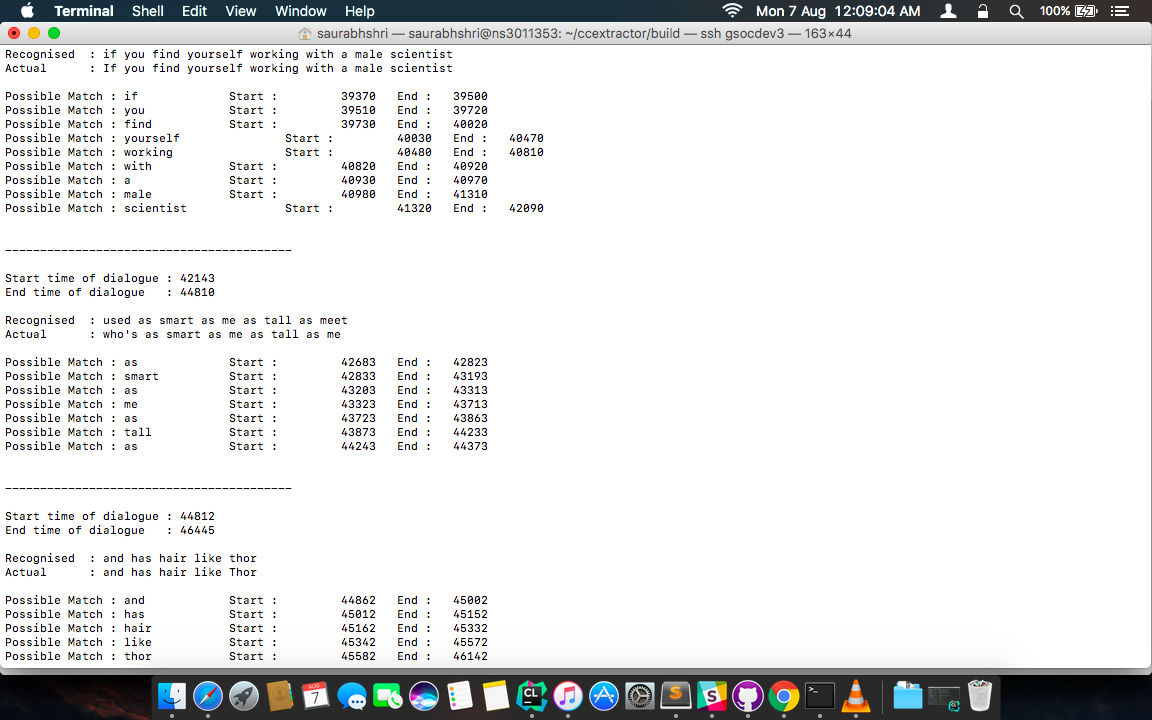
Once the match is found, the word is marked as recognised and it’s starting and ending timestamps are initialised.
There are various output options added in which the results can be visualised. One of those options is addition of output as Karaoke mode. In this, the words that is being spoken is written in SRT format with a <font> tag. So, when the word is being spoken,it gets highlighted. Here’s a gif with the excerpt from the respective karaoke subtitle file. This subtitle file was the result of karaoke output from ccaligner.
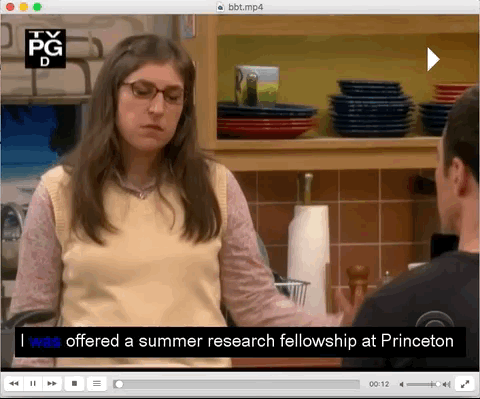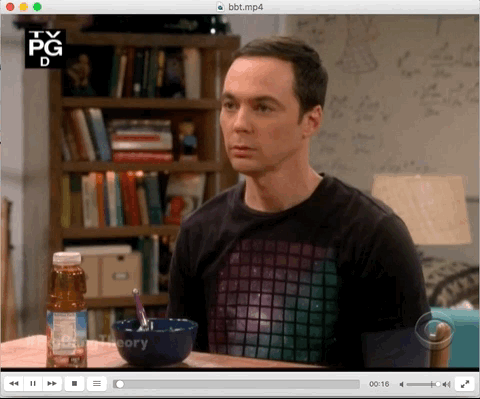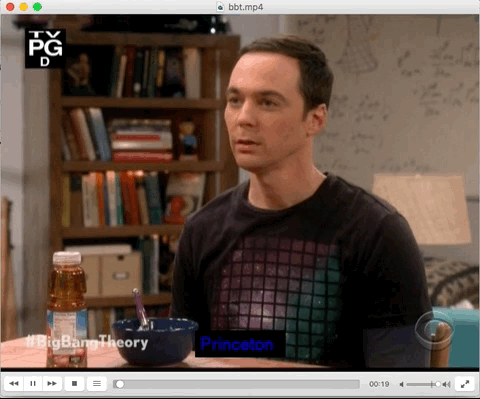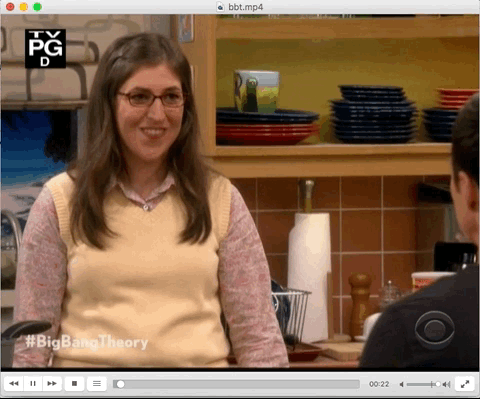
Output Visualised as in Karaoke format --print-as-karaoke yes .
00:00:12,780 --> 00:00:12,911
<font color='#A1E4D3'> I</font> was offered a summer research fellowship at Princeton
00:00:12,810 --> 00:00:13,100
I <font color='#0000FF'> was</font> offered a summer research fellowship at Princeton
00:00:13,180 --> 00:00:13,540
I was <font color='#0000FF'> offered</font> a summer research fellowship at Princeton
00:00:13,550 --> 00:00:13,900
I was offered <font color='#0000FF'> a</font> summer research fellowship at Princeton
00:00:13,910 --> 00:00:14,290
I was offered a <font color='#0000FF'> summer</font> research fellowship at Princeton
00:00:14,300 --> 00:00:14,680
I was offered a summer <font color='#0000FF'> research</font> fellowship at Princeton
00:00:14,690 --> 00:00:15,130
I was offered a summer research <font color='#0000FF'> fellowship</font> at Princeton
00:00:15,140 --> 00:00:15,250
I was offered a summer research fellowship <font color='#0000FF'> at</font> Princeton
00:00:15,260 --> 00:00:15,940
I was offered a summer research fellowship at <font color='#0000FF'> Princeton</font>
Then I worked on creating helpful demonstration for my evaluation. In my first evaluation, proper demo were missing and it impacted my evaluation. So, I made sure, it was not the case this time. This involved creating a simple user interface so that arguments could be issued to check the developed functionalities so far. Of course this UI was just for testing and was not very polished. I also created a simple batch script for dependency installation. If you want to try out the work so far, you may find detailed installation usages in the readme file in the repository. As always, the recent commits are in development branch. To try, simply do
./ccaligner --print-aligned color -in input.wav -srt input.srt
I would like to apologise for delayed posts and documentations. I am already in the college as I can not afford to miss it more. I am trying to balance all the aspects of the project, college and placement and I hope to come on track soon! The next post shall cover my mid term evaluation and the changes I made during it. It pretty interesting and climatic I would say. 😉 I hope other participants are having fun, and are doing good! See you in the next one! 🖖🏻