Almost two weeks have passed since the first evaluations and my last blog post. This blog post lays down the summary of work I’ve done in past two weeks, and is the first time I am writing a combined blog post of more than one week.
If you’re wondering why I haven’t updated the checklist till now, the answer is simple - I am discovering things on the go. Determining and forcing rigid checklists would only make my work restrictive. I will continue uploading the blog posts with the updates as always. I have major deliverables in my mind as per the proposal, and will be listed in the checklist before evluations. If you are interested in reading my project proposal, it could be found here.
I started working on implementing ASR (Automatic Speech Recognition) in the project as soon as I passed my first evaluations. In the phase 1 of coding period, I built the foundation of the tool, upon which the core alignment has to be built. I also made an approx aligner to aid in the task. By the end of the first phase, the project has met following milestones :
- Tool for subtitle processing and basic testing architecture.
- Sample repository.
- Algorithmic and Probability based word - audio matching.
- Audio processing.
- VAD implementation.
In the past two weeks, I have started the work of analysing audio to recognize words. This involves using ASR. I am currently using CMU’s PocketSphinx for this task. Maybe in the future I’ll add more ASRs like Kaldi or Google Speech Recognition et cetera. PocketSphinx is a (relatively) lightweight, speech recognition engine, specifically tuned for handheld and mobile devices, though it works equally well on the desktop. It’s written natively in C and has wrappers in huge number of languages such as Python or even JS.
Since, the project needs to be - not just an academic tool , the trade off needs to be among resource requirement and accuracy. PocketSphinx kind of stand in the middle of the niche. Plus, thanks to Nickolay V. Shmyrev’s for his tireless work at answering questions on forums and groups, the help is few messages away.
The very first step was to get PocketSphinx compile using CMake, since that is what I was using to build the tool. This also meant ensuring that it compiles across all platforms. The tutorial recommends installing PocketSphinx but there was no tutorial for compilation to be used as API. After lots of ‘trial and error’, I ended up collecting all the .c by recursively going through both PocketSphinx and SphinxBase libraries and then creating object files using them. Since, I am not compiling them the ‘recommended way’, there are certain flags, that remain unset. So, I had to manually set them. If you ever need to compile PocketSphinx in the same way, you may look at the CMakeLists.txt file in the main directory the project. If you have some better alternatives, PR are most certainly welcomed! 😊
After getting it to compile, I tried incorporating it with existing audio pipeline, and it works just fine. I first tried to use it directly on the approx locations, but soon realised that all it yielded me was garbage. It makes sense because we need to mark that starting and ending of “utterances” properly in order for successful recognition. It would need more than just taking some arbitrary window and expecting it to work.
Upon processing one sub at a time, I found out that the accuracy was very bad, it indeed recognizes some words, but for rest, it was out of bounds.
Recognised : an exalt are so i'm
Actual : So, in the next half hour or so,
This was expected as it does not make use of the transcription we already have.
So, the next step was to generate a custom language model based on available transcription. The ngram model is generated using CMUCLMTK toolkit. I generate the dictionary containing phonemes using the g2p-seq2seq tool. Currently they are invoked using system commands. I have also started using a new, better acoustic model which has significantly increased the accuracy of the recognition.
Recognised : exploring your vision for one exciting future might look like
Actual : exploring your vision for what an exciting future might look like
Recognised : so this is makes the first question a little ironic
Actual : which I guess makes the first question a little ironic
So, basically, I process chunks of samples based on timings present in subtitles. I mark utterance using the beginning time of subtitle and process samples that fall in the duration of the dialogue. I mark end of utterance and find hypothesis. Then I find the times of the words using the segment iterator. In case you’re looking to implement the same, the function looks something like this :
bool Aligner::printWordTimes(cmd_ln_t *config, ps_decoder_t *ps)
{
ps_start_stream(ps);
int frame_rate = cmd_ln_int32_r(config, "-frate");
ps_seg_t *iter = ps_seg_iter(ps);
while (iter != NULL) {
int32 sf, ef, pprob;
float conf;
ps_seg_frames(iter, &sf, &ef);
pprob = ps_seg_prob(iter, NULL, NULL, NULL);
conf = logmath_exp(ps_get_logmath(ps), pprob);
printf(">>> %s \t %.3f \t %.3f\n", ps_seg_word(iter), ((float)sf / frame_rate),
((float) ef / frame_rate));
iter = ps_seg_next(iter);
}
}
So far so good. :) This works with good accuracy, but not very good.
I really thought having subtitles will make the work easier as we already have some time information and order in which the words are spoken.
I tried creating FSG as :
If subtitle was :
00:00:04,960 --> 00:00:06,536
Thanks for having me.
Resultant FSG file was
FSG_BEGIN SAURABH
NUM_STATES 5
START_STATE 0
FINAL_STATE 4
# Transitions
TRANSITION 0 1 1.0 thanks
TRANSITION 1 2 1.0 for
TRANSITION 2 3 1.0 having
TRANSITION 3 4 1.0 me
FSG_END
In few cases it helps recognize the words perfectly, but this makes it too restrictive. For the parts where the recognition is something else or there were some other utterance, I get
ERROR: "fsg_search.c", line 940: Final result does not match the grammar in frame 44
I am hoping to make it flexible so that it still knows that the next word to recognize is ‘X’, and it becomes easier for it, but at the same time not fail.
Nikolay, suggested to include the garbage loop in the FSG to make it a little flexible. He was very kind to draw me a state diagram depicting the hints to what to do.
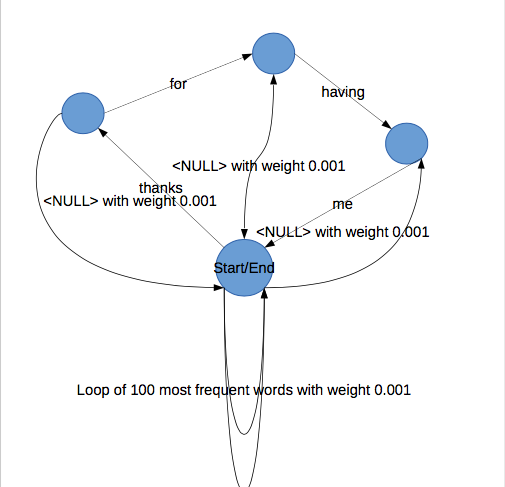
The next task will be to convert this into FSG programatically for all subs. Also, now since I have the timestamps of the words being spoken, it’s time to do the alignment. The difficult part will be for the words which are not recognised, and based on the type of speech in audio, sometimes they can be large. One way is to assign approx timestamps where the words couldn’t be recognised. I’ll let user enable/disable this with an argument.
On the personal front, my college is resuming quite earlier than I anticipated. Let’s see how it goes. I am still trying to figure out, if I should join right now or not. Since I am stepping into final year, the pressure for attendance should be low (as is usually the case). Let us see how it goes. I hope everything goes fine, because managing both college and full time GSoC project won’t come easy. In worst case, I might have to join college soon. In that scenario, I’ll try to cover-up by working extra on weekends. Also, I need to stress less probably. It’s been a long time I haven’t watched any movie, and ever since Silicon Valley’s season ended, my Monday entertainment ended as well. I loved the new spiderman in Captain America : Civil War, and I hope I get to able to watch the third reboot : Spiderman Homecoming soon. I have to do shopping as well for my college. Since, it’s placement season this semester, I will need formal clothes. I honestly don’t like shopping, specially if it’s related to clothes. I am already nervous and tensed about placements and all these formalities do not help at all.
Do you guys have any suggestions or tips? Feel free to comment / message me about it! 🙂 I hope other participants are having fun working on their projects. I can feel the stress sometimes when things don’t work as I planned them. I am really lucky to be in such an encouraging community who always somehow is able to cheer me and motivate me. Hopefully, everything shall work out good! 🕊