It has been two days since Google Summer of Code’s first of thirteen weeks ended. I have started working on my project CCAligner - Word by Word Audio Subtitle Synchronization with CCExtractor Development.
My progress could be tracked through weekly checklist for milestones and tasks, which can be accessed here : https://saurabhshri.github.io/gsoc/ .
With the end of Community Bonding Period, the coding period officially began. This is how I spent the first week of coding period :
-
Setting-up the new server. 💻
As I mentioned in the last post, I was already done with setting-up my development environment. But I had made a request for a dedicated server of my own with root access and Carlos (CCExtractor Org admin, my co-mentor) got me one! :) It’s a nice little server running Ubuntu Server. This was the first time I used such a vanilla version of linux. It’s super light out of the box and has absolutely nothing (just the linux) installed. It was so much fun setting up the server according to my preferences.
I also installed x2go in it so that I can also “visually” see the changes I am making. It’s super-helpful while debugging.
-
Started building basic skeleton of tool.
CCAligner can be found on Github at : https://github.com/saurabhshri/CCAligner/
I made a rough sketch of how the general hierarchy will be in the project. I will try to make my tool as modular as possible, and also in the way that it can be easily used as a library in other projects. It’s often difficult to “librarise” the code after creating, so even if it consumes some extra time, it’s better in my belief to begin doing the same.
In general, there are two main directories inside the
sourcedirectory -lib_ext: This shall contain all the external libraries that I’ll use.lib_ccaligner: This shall contain the CCAligner library.
├───demo │ ├───ApproxAligner | └─── ... ├───src │ ├───lib_ccaligner | | ├─── ... │ | └─── ... │ └───lib_ext │ ├─── ... │ └─── ... └───tests ├─── ... └─── ... -
Begin writing the implementation of approximation based word tagging.
Using the subtitle parser I created, I began writing the implementation of approximating the timestamp of a word based on it’s weight (calculated as a function of ratio of word length to sentence length). This is a super fast method to calculate the timestamp of each word and doesn’t require any type of audio processing. But obviously, this has very poor accuracy. Nonetheless this shall come in handy where audio - analysis is not feasiable and we require the sync super-fast without caring much about accuracy. Not to forget, this will provide us with a better window to analyse the word when audio analysis will come into the picture.
Since, the code is in the form of library, it’s very easy to use. The demo can be found in the
demodirectory which is linked here.#include "generate_approx_timestamp.h" int main() { std::cout<<"Enter path to the subtitle file : "; std::string filename; std::cin>>filename; ApproxAligner * aligner = new ApproxAligner(filename); // that's it :) More customization to come! aligner->align(); return 0; }It has room for ton of improvement, which I definitely will do with the course of time. Everything is currently pretty raw, as you’ll expect a software to be in it’s primary stages. And yes, I’ll begin naming my header files in a better way! :P
-
Set-up a small testing environment. ✔️
As mentioned in the last post, I have collected quite a lot of samples, a mojority of which are Ted talks (as they have clear speech as well as good subtitles). Previously I worked on improving CCExtractor Sample-Platform’s difference showing library. I extended this so that I can compare the output of the tool with the actual results, and also to compare results across various techniques.
I have also set-up Travis-CI to check builds across linux and OSX with every commit to the repository. Soon, I’ll add the test scripts to it as well. This will be a step towards test driven development.
-
Start implementation for audio based processing.
The very first step in this region was being able to read audio files and extract data. For this my code should be able to take wave file as input, check if the file is valid or not, and then decode it to extract information such as SampleRate, BitRate, etc. and the samples (which contain the audio data) itself. This was an intresting job. While I could find some code online that did the reading, but they were not utilising the object oriented approach and also, did not read the data in the manner desired for my use.
So, I searched for the wave file specifications online. The official Microsoft’s document was not the example of best specification-documentation I have seen, but was OK. Fortunately, I found another one which was very well written, and was precise. If you are interested, it is located here.
I did encounter few bugs while decoding wave files. Though the bugs were pretty small and easily fixable, they took some time to get spotted.
1.When I read the wave files in buffer, and used it to create a new wave file, for no apparent reason, the output was a very scattered and noisy version. Now, it felt pretty ridiculous to me that how can the output be different if all I am doing is reading it as it is and sending it as output.
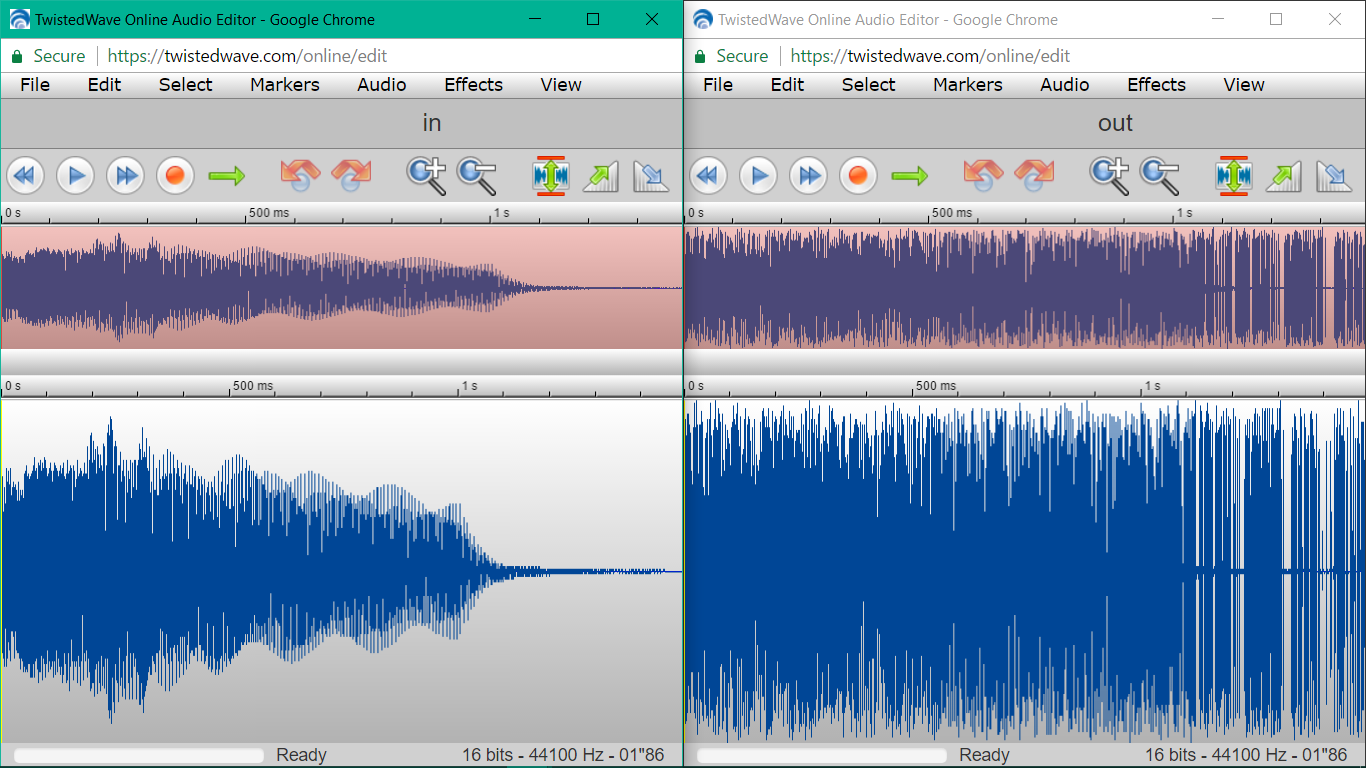 Difference in input and output wave files.
Difference in input and output wave files.After spending some time on it, I ended up opening both the input and output wave files in a hex viewer and search for the differences. After few bytes, I could see that the hex code shifted by one, i.e.
632e ca30 0a2d 582f 4c2b 8c2d 032a 2b2c 632e ca30 0d0a 2d58 2f4c 2b8c 2d03 2a2bNow, it became clear. Everywhere in the file,
0awas replaced by0a0d. Now this immediately raised a question in my mind. Could it be..? I Googled it, and yes! It was the endline characters. All theLFwere converted toCRLFleading to the distortion in the output file. Turn out, while I was reading the file in binary format, I was writing it in the text format, which led to this fiasco. Once the bug found, setting theios::binaryflag was all it took.2.Another intresting thing that happened was, everything was being decoded perfectly, except the SampleRate. This was strange because it was in the middle of various value - which were decoded perfectly. I had to read the detailed specification to find out that the data is in the form of unsigned values. I had not considered it and I was storing it in signed char. So, where the values should be, say for example, 255 it stored -128.
3.The specs which I used for reference were incomplete. It missed the fact that the wave file is not necessarily 44 Bytes and that it may contain some meta-data. So, to find the data subchunk, I manually searched for them in the stream.
At the end, the wave files are now being correctly read, and the the samples are collected as a vector of 16 bit integers (unsigned short int) :
vector<int16_t> _samples. -
Read about various available VAD techniques.
I researched about various available VAD techniques, compared their pros and cons and at the end decided to go with Google’s webRTC. They have one of the best VADs out there and the code is already in C. It’s documentation to use the native C code is almost non-existant. While I was able to locate the function that performs VAD by peeking into the files myself, it was not very clear about the arguments that needed to be supplied.
I did search the discuss-webRTC Google group, but there was nothing to be found in the forum. I even asked them on their IRC channel, but I was instructed to ask the question on StackOverflow, which I did. I was not very sure that someone would answer and when I saw the stats for webRTC related question, that increased my suspicion.
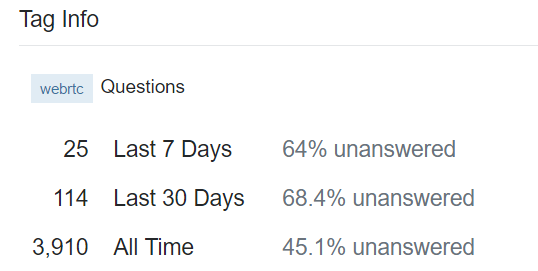
68.4% Questions Unanswered in last 30 days.Fortuantely I found out that there is a python wrapper of webRTC’s VAD in the Github. I immediately sent an email to John Wiseman, who created the awesome py-webrtcvad and asked him if he could help. Now, I wasn’t sure that I would find a reply. So, I looked into the SO stats to see the “most active” members on the webRTC tag and also emailed two people from there.
I was surprised to find that all the three people replied and all were willing to help. This is what I love about the open source community, everyone is eager to help. ❤️ Sometimes this comes rather surprising to me. Thank you John, Ajay and Gilad. :)
So ultimately John answered my question on SO, and I have a small implementation of VAD ready. In the coming weeks I’ll improve it and bring it to use.
-
Fixed the CMake build script of CCExtractor for windows.
CCExtractor had broken CMakeLists.txt since a long time. Due to this, the only way to compile it on Windows was using Visual Studio. I prefer to work in CLion so I spent some time and fixed the CMake list. It should also be helpful in bringing the Windows support to Sample-Platform which can use this to build it.
What’s next?
This was the first of total thirteen weeks. There’s a lot of work left. The work already done is also pretty raw and there’s a room for tons of improvement. My mentors have suggested a few changes as well. E.g. The tool needs to be able to read directly from the stream (like the data being piped from FFMPEG). I will stick to the timeline and continue the work. I am in constant contact with my mentors and shall work in accordance with their feedbacks.
The second week has already commenced and the evaluations are in the June end. I hope other GSoC participants are enjoying their work as well! 📈