Today marks the end of three of thirteen weeks of Google Summer of Code’s coding period. This week I implemented a simple user interface, added various output formats, fixed some bugs, fixed Unix build and processed samples.
All the latest commits could be found in the
developmentbranch. I will merge them tomasteronce the first phase completes.
The code written till now is arranged systematically and is in the form of library so that anyone can use it in her code and make use of the available functionalities.
Say, for example, you want to make use of Approx Aligner (to perform approximate word by word audio subtitle synchronization) in your own cool project. All you need to do is, clone the CCAligner repository and put it in your project directory. Then simply include the “generate_approx_timestamp.h” file in your project by providing appropriate path. Also, include all the other files in your CMake file, and you are good to go! You can then simply do ApproxAligner * aligner = new ApproxAligner(input_filename); and use appropriate functions for your use. 😎
I am trying to include all the examples in the /demo directory in the repository. You can find it here. They have their own CMakeLists.txt in the respective directories so that you can build them individually if you want to. I will add a demo install script later in which you should be able to pass the demo you want to see as a parameter and it’ll build it for you.
While it’s great for developers to use this, there was no way to use it just out of the box. So, I have built a small user interface so that it should be easy to use and try and maybe use it as a base to develop your application. This enables using the tool directly after cloning it and then building it. The interface is pretty minimal and is command line only. You can run the tool without any arguments to see the available options. I will be updating the readme file with the instructions once it is complete.
Here’s a snippet of the same :
ApproxAligner : ccaligner -a input.srt
ccaligner -a input.srt -of <output_format>
(srt/xml/json/stdout)
e.g. ccaligner -a input.srt -of xml
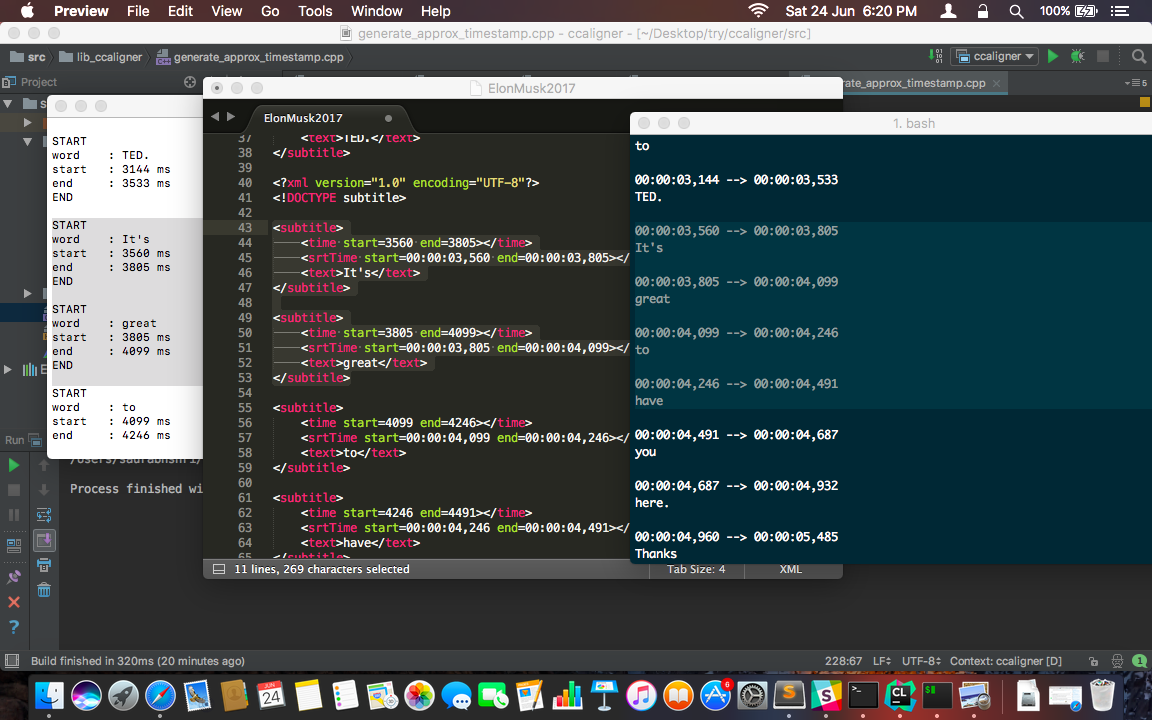
As evident from the above usage examples, there are now options available to have output in more than just SRT format. The output can currently be obtained in the form of SRT, XML, JSON format and also on stdout. The structure of all of them is shown below. The respective functions can be edited and extended to user desired scheme.
/* printToXML() */
├───Subtitle
├───Start Time
├───End Time
├───Start Time in ms
├───Start Time in ms
├───Word
├───Style
| ├───Style Tag 1
| ├───Style Tag 2
| └───Style Tag
Example :
<subtitle>
<time start=3560 end=3805></time>
<srtTime start=00:00:03,560 end=00:00:03,805></srtTime>
<text>It's</text>
</subtitle>
<subtitle>
<time start=3805 end=4099></time>
<srtTime start=00:00:03,805 end=00:00:04,099></srtTime>
<text>great</text>
</subtitle>
/* printToConsole() */
START
word : {word here}
start : {start time in ms}
end : {end time in ms}
END
Example :
START
word : It's
start : 3560 ms
end : 3805 ms
END
START
word : great
start : 3805 ms
end : 4099 ms
END
 🔥
🔥
Also the Unix build (Linux and MacOS) was failing ever since I added the VAD. The webRTC library failed to link. Turns out, webRTC uses WEBRTC_POSIX variable to determine if the system is POSIX. But for some reason, this variable did not get set. It wasn’t apparent at first that this is the problem. After a lot of digging deep I found that this was the culprit. I had to add a manual check for posix systems so that correct multithreading code executes in respective environment.
Once this was fixed, it turned out while the pthread library successfully links in MacOS, it wasn’t linking it in Linux. Supplying -lpthread as a flag while linking solved the problem. The CMakelist.txt was modified to incorporate all these changes. The same was reflected in the VAD demo as well.
Also, there’s a special requirement of type of wave files that are needed by ASR and VAD library. The wave file must be 16 bit PCM, Mono, 16Khz or 8Khz sampled. So, I processed the samples to obtain the wave files.
What’s next?
I originally planned to do the video chunking, i.e. splitting the videos such that they only contain the parts where audio is present. But for now I am planning to postpone it as it totally relies on the way that will be best suited as per ASR’s requirement. So, I will do it at that time.
I will now add the capability to read the wave file from stream i.e. in a way that data can be piped through other programs such as ffmpeg. So that doing something like ffmpeg -i video <other params> | ccaligner will be possible. I will also be working on adding sliding window approch to VAD to get better results. It should be interesting to see if it improves the accuracy.
I will be preparing a full report of the progress so far, complete the documentation, update the same on ccextractor.org et cetera.
Also, 28th is the date when Carlos has decided to read the report so that he can submit the evaluation. The evaluations start on 26th and are due before 30th. I am a bit nervous (bit >= 64) as this is the first evaluation ever I am facing in my entire life. I hope everything goes good. I am very happy with my mentors, they are super nice and super fun to work with. I am glad that they trusted me enough to be in the driver’s seat for this project.
All the very best to all the GSoC participants for their very first evaluations. I hope you all (inlcuding me) pass with flying colours! 🌈